
皆さんこんにちは。合同会社StudioData代表のRyumaと申します。
今回は機械学習の「分類問題」について学習した内容を5分で振り返ります。
なお、学習に使用した参考書は『Pythonによる機械学習入門』ですので、興味がある方はぜひご購読くださいませ。
分類問題とは
分類問題とは、「正解付きデータを学習させる教師あり学習の1つ」と参考書などでは解説されますが、要するに「元々用意されたグループにデータを分けること」です。
例えば、ロボットが的に矢を当てるトレーニングをするとします。
矢を当てるべき的(ターゲット)は事前にロボットに知らせてあり、複数種類の矢をロボットに渡します。
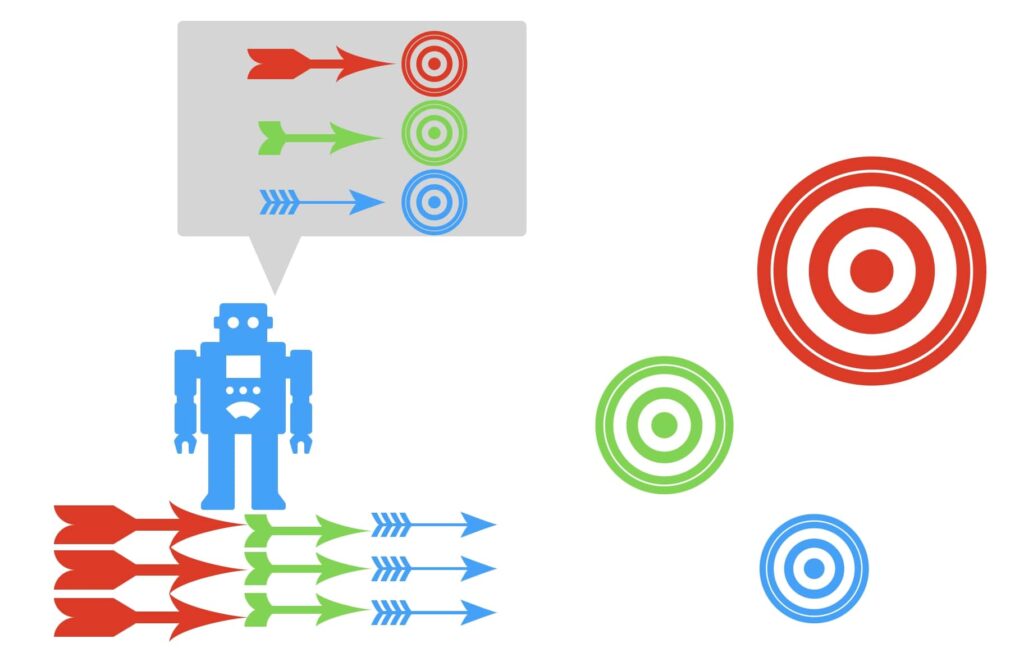
短い矢は近くの的、長い矢は遠くの的、中くらいの矢は中くらいの的、など「どの種類の矢をどの的に向かって射るべきかをロボットに学習」させ、新しい矢を渡したときに、学習通りロボットが正しい的に向かって矢を射れるようになることが教師あり学習の分類問題です。
簡単な分類器を作ってみる
分類器とは
分類器とは、用意されたデータをアルゴリズムに従って分けていくモデルのことです。
ロボットの例でいうと、用意された矢がデータ、矢を射るということがモデル、ターゲットからどれくらい離れているかを計算するのが目的関数、モデルのパフォーマンスが上がるように修正することが最適化アルゴリズムです。
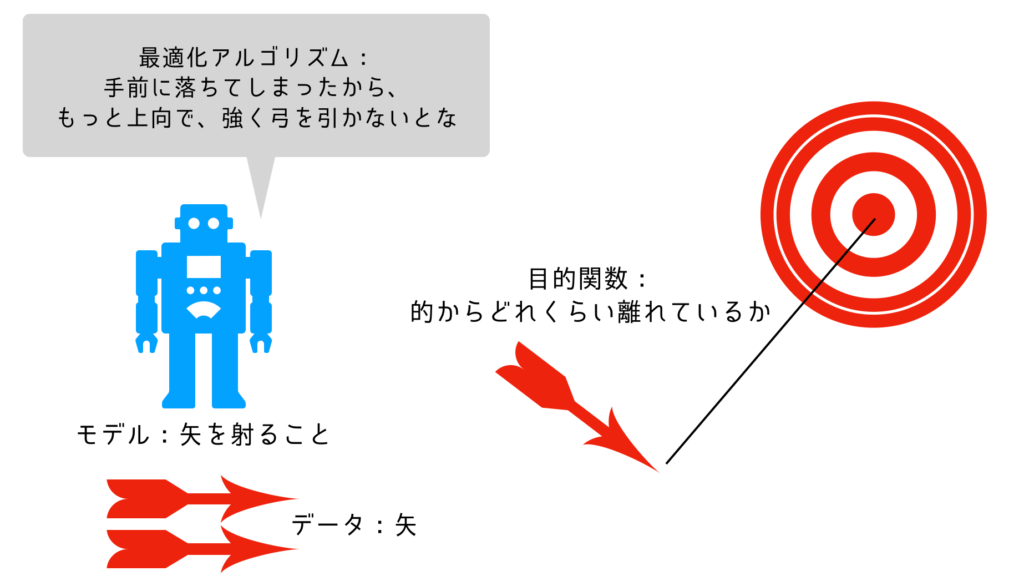
様々なデータ(矢)をモデルに通し(矢を射る)目的関数を使って(的からどれくらい離れているか)最適化アルゴリズムを施す(もっと強く弓を引こう、もっと上向き射ろうなど)ことを繰り返します。
これが何千回、何万回と施行されることで、ロボットはやがて的の中心に矢を射ることが出来るようになるのです。
digitsを使った画像データの分類
digitsデータセットとは、8*8ピクセルの手書き数字の画像データが0から9まで存在するデータセットのことです。
まずはjupyter環境でdigitsを出力してみます。
# 必要なライブラリのインポート
import matplotlib.pyplot as plt
from sklearn import datasets
# digitsデータをロード
digits = datasets.load_digits()
# 画像を2行5列に表示
for label, img in zip(digits.target[:10], digits.images[:10]):
# 複数画像を表示するためにsubplotを使う
plt.subplot(2, 5, label + 1)
plt.axis('off')
# imshowで画像を表示
plt.imshow(img, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Digit: {0}'.format(label))
plt.show()
モノクロの画像データが10枚出力されました。これを使って分類器を作ってみます。
今回は3と8の画像の違いを読み取り、正しく分類する分類器を作ってみましょう。
# 必要なライブラリのインポート
import numpy as np
from sklearn import datasets
# digitsの読み込み
digits = datasets.load_digits()
# 3と8のデータ位置を求める
flag_3_8 = (digits.target == 3) + (digits.target == 8)
# 3と8のデータを取得
images = digits.images[flag_3_8]
labels = digits.target[flag_3_8]
# 3と8の画像データを1次元化
images = images.reshape(images.shape[0], -1)
# ===========================================
# 分類器の作成
# sklearnからtreeをインポート
from sklearn import tree
# 3と8の画像データを1次元化
images = images.reshape(images.shape[0], -1)
# 分類器の作成
n_samples = len(flag_3_8[flag_3_8])
# 全体のデータの60%を分類器にかけてみる
train_size = int(n_samples * 3/5)
classifier = tree.DecisionTreeClassifier()
classifier.fit(images[:train_size], labels[:train_size])
# ===========================================
# 分類器の性能(正答率)を調べてみる
from sklearn import metrics
expected = labels[train_size:]
predicted = classifier.predict(images[train_size:])
print('Accuracy:\n', metrics.accuracy_score(expected, predicted))これを実行すると、これを実行すると、「Accuracy : 0.8741258741258742」と出力されます。
正答率は87%です。
学習データとテストデータ
先ほどのdigitsデータセットでは、学習データを全体の60%にするという作業を行いました。
機械学習は、データを以下の2つに分けて使うことがほとんどです。
- 学習データ:機械にパターンを学ばせるときに使うデータのこと
- テストデータ:学習をした結果得られるモデルを評価するのに使うデータのこと
試験勉強などでも、問題集を「答えを見ながら学習し公式を覚えることに使う」問題と「覚えたものを自分で使ってみる実戦練習に使う」問題と分けたりしますね。
同じように機械学習でも、半分を学習用に、半分を覚えた学習を試してみる用に使うのです。
その2つの結果が同じであればあるほど学習の精度が高いという結果になります。
機械学習の分類問題まとめ
機械学習【分類問題】の基礎的な部分を分類器を実際に作りながら5分で復習しました。
一からモデルを構築しようとせず、まずは何が書いてあるか、どの部分でどの動きを記述しているのかを理解することから始めようと思います。
最後まで読んでいただきありがとうございました!